We are living in a data-driven and globally interconnected world, and our data strategies need to recognise this to ensure that all users can interact with data in a way that is clear and culturally respectful.
This means that not only should data strategies include a metadata strategy that ensures data is well documented, it also means that data strategies should include a multilingual metadata strategy that helps organisations document data across multiple languages to ensure compliance with relevant cultural and legislative expectations.
Many countries such as Canada and Switzerland have a long culture of bi- or multilingual communication at all levels of government. More recently however, countries such as Ireland and New Zealand are introducing multi-language initiatives to support access by indigenous and marginalised communities to data of cultural importance. Even in an officially “monolingual” country like Australia over a quarter of all Australians speak multiple languages with many people indicating that English is a second language.
To support this strategic need to improve cross-cultural access to data, organisations globally need tools that enable them to consistently document their metadata across multiple languages in a consistent way that improves information discovery.
That is why this Monday 21 February 2022 on United Nations International Day of the Mother Tongue, we are proud to announce the upcoming launch of a new multi-lingual library for the Aristotle Metadata Registry and the Tablion Data Portal that allows organisations to quickly and accurately document their data in a culturally respectful multilingual manner.
From next week, administrators of all Aristotle Metadata products can start defining the languages used across their registries to ensure that users can interact with their data in the language they know best. These new multilingual features will allow users to document, discovery and request data using languages they are most comfortable with as a way to make access to data more equitable and fair for all users.
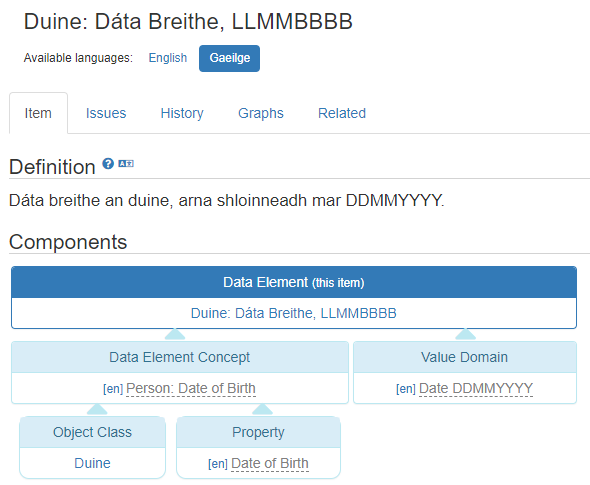
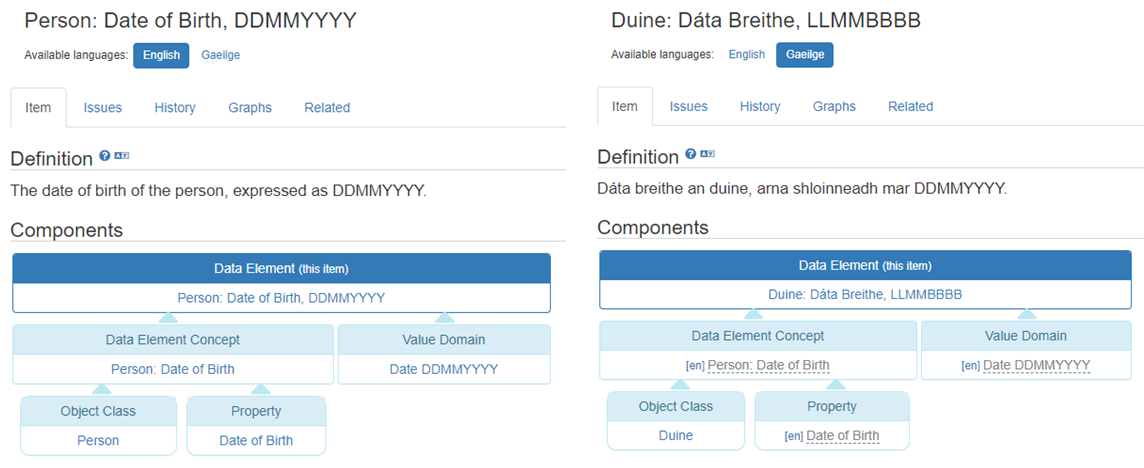
Beyond just capturing synonyms, every metadata item can now store name and definitions, codes and classifications all across multiple languages so that users know the equivalence between terms across languages for all business knowledge.
This new multilingual version of the Aristotle Metadata Registry will also provide safe, informative fallbacks so that when content isn’t available, they are shown information in a fallback language defined by the registry.
In the coming weeks we will be expanding our help and user guides to provide users with high quality steps and examples on how to introduce multiple language metadata to their registry.
We’re thankful for all of the feedback we received from our global beta-testers across Europe, New Zealand & Canada who helped refine this amazing new addition to the Aristotle Metadata Registry - and look forward to see our users make their data make sense for even more people around the world.
Stay tuned for more news about how we engineered this amazing new update using django-garnett the new multilingual open-source library we’ve built for the Django Web Framework.


